공개형 대형 멀티모달모델 ‘콜라보·모아이’ 출시
-
-

- ▲ 노용만 전기·전자공학부 KAIST 교수. /KAIST
KAIST(한국과학기술원)는 전기·전자공학부 노용만 교수 연구팀이 오픈AI의 GPT-4V, 구글의 제미나이-프로(Gemini-Pro) 등 기업에서 비공개하고 있는 상업 모델인 대형멀티모달모델(LMM)의 시각 성능을 뛰어넘는 공개형 LMM을 개발했다고 20일 밝혔다.
대형멀티모달모델이란 텍스트뿐만 아니라 이미지 데이터 유형까지 처리할 수 있는 대형언어모델을 말한다. 해외 대형 기업의 풍부한 컴퓨팅 자원의 지원으로부터 인간의 뇌에 있는 신경망의 개수와 유사한 수준초대형모델들이 만들어지고 있으나 학계에서는 이런 개발이 쉽지 않았다.
노용만 교수 연구팀은 단순히 모델의 크기를 키우거나 고품질의 시각적 지시 조정 데이터셋을 만들지 않고 LMM 시각 성능을 획기적으로 높인 콜라보(CoLLaVO), 모아이(MoAI) 2가지 기술을 연속적으로 개발했다고 밝혔다.
연구팀이 개발한 첫 번째 기술인 ‘콜라보(CoLLaVO)’는 현존하는 공개형 LMM이 비공개형 모델의 성능에 비해 현저하게 낮은 이유를 일차적으로 물체 수준에 대한 이미지 이해 능력이 현저하게 떨어진다는 것에서 찾았다.
해당 능력을 효율적으로 증가시켜 시각-언어 태스크에 대한 성능을 향상 하기 위해 연구팀은 이미지 내의 정보를 배경과 물체 단위로 분할하고 각 배경 및 물체에 대한 정보를 멀티모달 대형언어모델에 입력으로 직접 넣어주는 새로운 방법‘크레용 프롬프트(Crayon Prompt)’라는 시각적 프롬프트를 새롭게 제안했다.
시각적 지시 조정 단계에서 크레용 프롬프트로 학습한 정보를 잃어버리지 않기 위해 연구팀은 물체 수준 이미지 이해 능력과 시각-언어 태스크 처리 능력을 서로 다른 파라미터로 학습해 서로 간의 정보를 잃지 않게 만드는 학습 전략인 ‘듀얼 큐로라(Dual QLoRA)’더 제안했다.
이를 통해 콜라보(CoLLaVO) LMM은 이미지 내에서 배경 및 물체를 구분하는 능력이 뛰어나 일차원적인 시각 구분 능력이 크게 향상됐다.
-
-
-
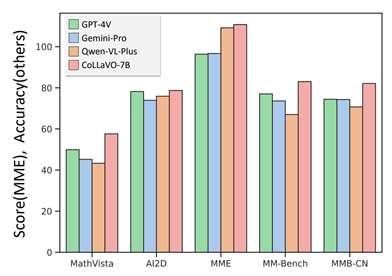
- ▲ 노용만 KAIST 전기·전자공학부 교수 연구팀이 개발한 콜라보(CoLLaVO) 멀티모달 대형언어모델 성능. /KAIST
노용만 KAIST 교수는“오픈AI GPT-4V와 구글의 제미나이-프로보다 시각 성능을 향상한 대형멀티모달모델을 개발했다”며
“연구팀에서 개발한 공개형 멀티모달 대형언어모델이 허깅페이스 일간 화제의 논문(Huggingface Daily Papers)에 추천됐고, 각종 SNS를 통해 세계 연구자에게 알려지고 있다”고 전했다.
한편, 콜라보(CoLLaVO)는 자연어 처리(NLP) 분야 국제 학회인 ‘Findings of the Association for Computational Linguistics(ACL Findings) 2024’에 지난달 16일 학회에 승인받았다. 모아이(MoAI)는 컴퓨터 비전 국제 학회인 ‘European Conference on Computer Vision(ECCV) 2024’학회 승인을 앞두고 있다. 이 연구는 KAIST 미래국방 인공지능 특화연구센터 및 전기및전자공학부의 지원을 받아 수행했다.
-
-
-
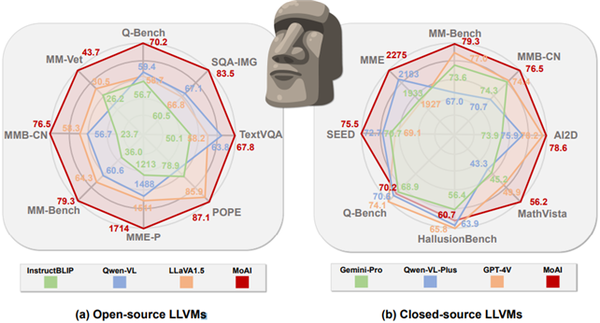
- ▲ 노용만 KAIST 전기·전자공학부 교수 연구팀이 개발한 모아이(MoAI) 멀티모달 대형언어모델 성능. /KAIST
-
- 구아현 객원기자 ainews@chosun.com