-
-
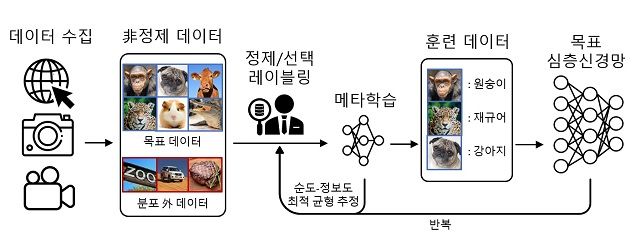
- ▲ 연구팀에서 개발한 메타 질의 네트워크 방법론의 동작 개념도. /KAIST
KAIST는 전산학부 이재길 교수팀이 딥러닝 훈련 데이터 구축 비용을 절감할 수 있는 ‘데이터 동시 정제 및 선택 기술’을 개발했다고 12일 밝혔다. 딥러닝이 인공지능(AI) 기술 중 상업적 활용도가 높은 점을 봤을 때 향후 AI 사업의 확장 속도가 더 커질 것으로 전망된다.
딥러닝은 많은 양의 데이터를 분석하고 학습해 최적의 결론을 도출하는 기술이다. 2016년 이세돌 바둑기사와 대결한 알파고는 과거 바둑 경기 데이터를 학습하며 최적의 수를 뒀다. 이 과정에는 각 훈련 데이터의 정답지를 만드는 레이블링 과정이 필요하다. 고양이 사진을 학습할 때 이 사진에 ‘고양이’라는 정답을 적어줘야 정확히 학습할 수 있기 때문이다. 이 과정은 일반적으로 수작업으로 진행되므로 많은 노동력과 시간적 비용이 소요된다. 따라서 AI 기업들은 훈련 데이터 구축 비용을 줄이기 위한 연구를 진행해왔다.
일반적으로 딥러닝용 훈련 데이터 구축 과정은 △수집 △정제 △선택 △레이블링 단계로 이뤄진다. 수집 단계에서는 웹, 카메라, 센서 등으로부터 대용량의 데이터가 정제되지 않은 채로 수집된다. 목표 서비스와 관련 없는 ‘분포 외 데이터’가 포함된다. 동물 중 재규어 사진을 수집할 때 자동차 브랜드가 포함되는 식이다. 이러한 분포 외 데이터는 데이터 정제 단계에서 정제돼야 한다.
이재길 교수팀은 기존 훈련 데이터 구축 과정에서 벗어나 정제와 선택을 한 번에 진행하는 방식으로 비용 절감을 이뤘다. 데이터를 정제할 때 딥러닝 성능 향상에 도움이 될 데이터를 우선으로 선택하는 방식이다. 데이터의 필요 여부는 주어진 훈련 데이터 구축 비용 내에서 최고의 효과를 내도록 데이터의 ‘순도 지표’와 ‘정보도 지표’의 최적 균형을 찾아 판단한다.
지금까지 딥러닝 훈련 데이터 구축 과정에서 수집과 정제를 분리해 놓았던 것은 순도 지표와 정보도 지표의 균형을 찾기 힘들었기 때문이다. 순도와 정보도는 일반적으로 서로 상충하므로 최적 균형을 찾는 것이 복잡했기 때문이다.
이 교수팀은 두 지표의 최적 균형을 찾기 위해 목표 심층신경망의 성능 향상을 위해 추가적인 상위 레벨의 신경망을 사용하는 ‘메타학습’을 적용했다. 기존 신경망에 작은 신경망 모델을 추가로 도입해 데이터 수집 과정에 선별 과정을 추가했다. 새롭게 선택돼 레이블링 된 데이터를 순도-정보도 최적 균형을 찾기 위한 훈련 데이터로 활용했고 레이블이 추가될 때마다 최적 균형을 갱신했다.
연구팀은 이 메타학습 방법론을 ‘메타 질의 네트워크’라고 이름 붙이고 이미지 분류 문제에 대해 다양한 데이터와 광범위한 분포 외 데이터 비율에 걸쳐 방법론을 검증했다. 그 결과 기존 최신 방법론과 비교했을 때 최대 20% 향상된 최종 예측 정확도를 기록했다. 또 모든 범위의 분포 외 데이터 비율에서 일관되게 최고 성능을 보였다.
이재길 교수는 “이 기술이 텐서플로우 혹은 파이토치와 같은 기존 딥러닝 라이브러리에 추가되면 기계 학습 및 딥러닝 학계에 큰 파급효과를 낼 수 있을 것”이라고 말했다.
이번 연구 결과는 최고권위 국제학술대회 ‘신경정보처리시스템학회(NeurIPS) 2022’에서 올 12월 발표될 예정이다.
-
- 김동원 객원기자 theai@chosun.com