의료 현장에서의 활용 가능성 기대
-
의료 인공지능(AI) 기업 에이아이트릭스(AITRICS, 대표 김광준)가 지난 6일부터 11일까지 인도 하이데라바드에서 열린 음성·신호처리 학술대회 ‘ICASSP 2025(International Conference on Acoustics, Speech and Signal Processing)’에서 음성 합성 기술 관련 논문 2편이 채택됐다고 15일 밝혔다. ICASSP는 음성·신호처리 분야의 최대 국제 학회 중 하나다.
이번에 채택된 논문은 소량의 음성 데이터로 특정 화자의 말투와 억양을 재현하는 음성 합성 모델과 얼굴 이미지에서 화자의 음성 스타일을 추론해 자연스러운 음성을 생성하는 제로샷 TTS(text-to-speech) 기법에 관한 것으로 포스터 세션에 소개됐다.
-
-
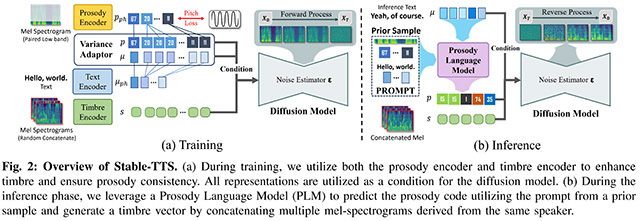
- ▲ 운율 프롬프팅을 통한 안정적인 화자 적응형 텍스트-음성 합성(Stable-TTS: Stable Speaker-Adaptive Text-to-Speech Synthesis via Prosody Prompting) /이미지 제공=에이아이트릭스
첫 번째 논문은 음성 합성 모델 ‘Stable-TTS’를 다뤘다. 운율 언어 모델과 사전 보존 학습 방식을 적용해, 기존 TTS 모델에서 나타날 수 있는 불안정성과 음질 저하 문제를 개선했다.
또 다른 논문에서는 얼굴 이미지에서 화자의 특성을 추출해 운율 정보와 결합하는 방식의 제로샷 TTS 기술을 소개했다. 얼굴 이미지와 음성 스타일 간의 매핑 정밀도를 높여 음성의 자연스러움을 높인 것이 특징이다.
-
-
-
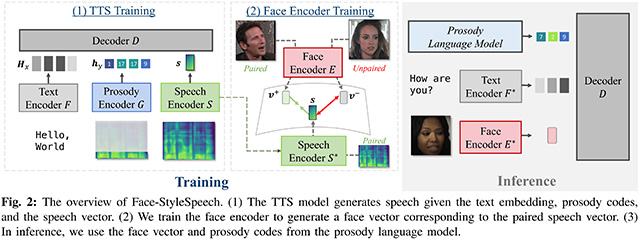
- ▲ 얼굴 이미지 기반 제로샷 음성 합성 성능 향상을 위한 개선된 얼굴-음성 매핑 기법(Face-StyleSpeech: Enhancing Zero-shot Speech Synthesis from Face Images with Improved Face-to-Speech Mapping) /이미지 제공=에이아이트릭스
한우석 에이아이트릭스 연구원은 “이번 연구는 텍스트 기반 LLM을 넘어, 음성과 이미지를 결합한 멀티모달 LLM 확장의 기술적 기반이 될 수 있다”며, “특히 의료 현장처럼 데이터 확보가 어려운 환경에서도 효과적으로 활용될 수 있을 것으로 기대한다”고 말했다.
-
- 김정아 기자 jungya@chosun.com
최신뉴스
Copyright ⓒ 디지틀조선일보&dizzo.com