이미지 검색 분야에서 최근 연구 중인 ‘제로샷 이미지 캡셔닝’이 주제
-
-
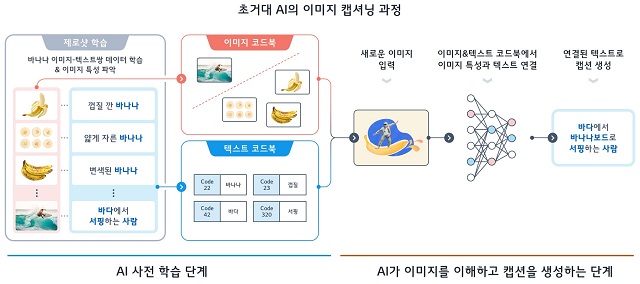
- ▲ 초거대 AI가 이미지 캡셔닝을 하는 과정. /LG
LG가 이미지를 생성하는 인공지능(AI) 기술을 넘어 ‘이미지를 설명하는 AI’ 보급 확대에 나선다. LG그룹에서 AI 연구와 개발을 담당하고 있는 ‘LG AI연구원’은 오는 2월 1일부터 4월 말까지 AI가 처음 본 이미지를 얼마나 정확하게 이해하고 설명하는지 평가하는 ‘LG 글로벌 AI 챌린지’를 온라인으로 개최한다고 31일 밝혔다. 사용자가 입력한 텍스트를 이해해 새로운 이미지를 생성하는 ‘이미지 생성 AI’ 기술에 더해 새로운 이미지를 AI가 설명하는 기술을 본격 상용화하려는 전략으로 풀이된다.
◇ 오픈AI도 아직 못 한 이미지 만들고 설명하는 기술 상용화
LG AI연구원은 텍스트를 이미지로 그려낼 뿐 아니라 이미지를 보고 텍스트를 설명할 수 있는 ‘멀티모달’ 기능을 갖춘 초거대 AI를 2021년 세계 처음으로 공개했다. 초거대 멀티모달 AI ‘엑사원’이다. 이미지를 생성하고 설명도 할 수 있는 기술은 ‘달리2’, ‘챗GPT’를 개발한 미국AI연구소인 ‘오픈AI’도 아직 상용화하지 못한 기술이다.
LG AI연구원은 지난해 경량화된 엑사원 모델을 선보였다. 기존 엑사원 대비 그래픽처리장치(GPU) 사용량을 63% 줄이면서도 AI 개발 속도를 좌우하는 추론 속도는 40% 높였다. 사용 전력을 줄이고 속도는 높여 실제 산업 현장에 쉽게 적용하기 위해서다. 이번 대회는 이 경량화 모델을 기반으로 일반 소비자도 엑사원 기능을 경험할 수 있게 마련했다.
이번 대회는 공동연구센터를 통해 엑사원을 함께 연구 중인 ‘서울대학교 AI대학원’과 이미지 캡셔닝 AI 상용화 서비스를 공동으로 준비 중인 ‘셔터스톡’과 함께 진행한다.
셔터스톡은 편향성과 선정성 등에 대한 AI 윤리 검증을 끝낸 고품질의 이미지-텍스트 데이터셋 2만 6000개를 무료로 제공한다. 해당 데이터셋은 사진뿐 아니라 일러스트레이션, 그래픽 등 다양한 형태의 이미지를 포함하고 있어 대회 참가자들은 저작권과 비용, 품질에 대한 고민 없이 자신들의 AI 모델 최적화와 성능 평가를 진행할 수 있다.
-
-
-
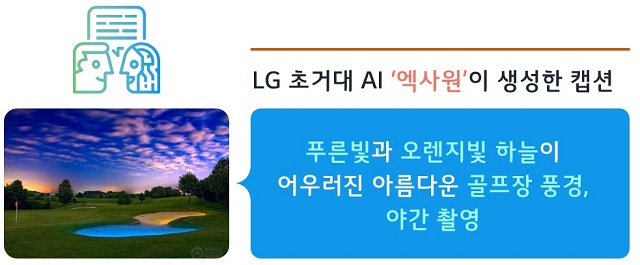
- ▲ LG 초거대 AI ‘엑사원’이 생성한 이미지 설명 예시. /LG
◇ 챗GPT 이후 반향 예상되는 ‘제로샷 이미지 캡셔닝’이 주제
이번 대회는 ‘제로샷 이미지 캡셔닝’ 기술을 주제로 한다. AI가 마치 사람의 시각 인지 능력처럼 처음 본 사물이나, 동물, 풍경 등이 포함돼 있는 이미지를 봤을 때나 일러스트레이션, 그래픽 등 표현 방식이 다른 이미지를 봤을 때 기존 학습한 데이터를 기반으로 스스로 이해하고 유추한 결과를 텍스트로 설명할 수 있는 기술이다. 토끼를 한 번도 본 적이 없는 사람이 토끼 여러 마리와 고양이 한 마리가 함께 있는 것을 봤을 때 동물들의 생김새와 특성의 공통점과 차이점을 학습하고 ‘토끼도 털은 있지만 고양이와는 다르게 귀가 길고, 뒷다리가 발달했다’라고 설명할 수 있는 것과 유사한 기술이다.
LG AI연구원은 제로샷 이미지 캡셔닝 기술이 고도화되면 이미지 인식 AI 기술의 정확성과 공정성이 향상되고 결국 사람들의 실생활에 직접적으로 도움을 줄 수 있는 기술 개발로 이어질 수 있다고 설명한다. 하루에도 방대한 분량의 이미지 데이터들이 온라인상에 올라오고 있는데, 이 기술을 활용하면 AI가 자동으로 캡션과 키워드를 생성해 검색의 편의성과 정확도를 높일 수 있다는 설명이다. 또 의학 전문 데이터를 추가 학습할 경우 의학 영상을 분석하는 ‘의학 전문가 AI’로 활약할 수 있다고 덧붙였다.
LG AI연구원 관계자는 “최근 자연어 검색 분야에서 반향을 일으키고 있는 챗GPT처럼 이미지 캡셔닝 기술은 이미지 검색 분야에 혁신을 가져올 것”이라면서 “AI가 스스로 이미지를 이해하고 설명하며, 해시태그도 달 수 있기 때문”이라고 말했다.
이경무 서울대 AI대학원 석좌교수는 “이미지 캡셔닝은 영상에 나오는 객체들의 관계부터 상황과 문맥까지 이해해 인간의 언어로 표현하고 설명하게 하는 것으로 AI가 인간의 지능에 얼마나 가까워졌는지 보여주는 하나의 척도”라며 “학습 데이터 없이도 이러한 작업을 수행하는 제로샷 이미지 캡셔닝은 매우 도전적인 문제이자 세계적으로도 최근에 연구가 시작된 분야”라고 설명했다. 이어 “LG AI연구원과 서울대 AI대학원, 셔터스톡이 세계 최초로 챌린지와 워크샵을 공동 진행하는 것은 우리나라의 AI 역량이 이미 세계적인 수준에 도달했다는 것을 의미한다”고 평가했다.
◇ AI 국제 학회인 ‘CVPR 2023’에서 ‘제로샷 이미지 캡셔닝’ 워크샵 개최
LG AI연구원은 제로샷 이미지 캡셔닝 기술 보급 확대를 위해 올해 6월 캐나다 밴쿠버에서 열리는 컴퓨터 비전 분야 세계 최고 권위 학회인 ‘CVPR 2023’에서 ‘제로샷 이미지 캡셔닝 평가의 새로운 개척자들을 주제로 워크샵을 진행한다고 밝혔다. 구글, 마이크로소프트 등에서 AI 연구를 진행하고 있는 산업계 전문가들을 비롯해 글로벌 석학들과 함께 이미지 캡셔닝 기술 연구의 방향성과 확장성, AI 윤리 문제에 관해 심도 있는 논의를 진행할 계획이다. ‘LG 글로벌 AI 챌린지’ 최종 수상팀은 이날 워크샵에서 성과를 발표할 기회가 주어진다.
김승환 LG AI연구원 비전랩장은 “LG AI연구원은 현재 생성형 AI 뿐 아니라, 객체를 인식하는 기술 수준을 넘어 인간 수준으로 영상까지 이해하는 AI로 퀀텀 점프할 수 있는 가능성을 확인했다”고 말했다. 이어 “세계적인 학회에서 영상 이해의 핵심 기술이자 기반 기술인 이미지 캡셔닝을 주제로 대회를 개최한 것은 LG가 컴퓨터 비전 분야의 글로벌 입지를 보여준 계기”라며 “이번 대회를 통해 전 세계 AI 연구자들과 함께 연구의 의의와 필요성, 그리고 확장 가능성에 관해 함께 논의하는 장을 만들고자 한다”고 말했다.
-
- 김동원 객원기자 theai@chosun.com